[video title=”斗地主演示视频 “ url=”/usr/uploads/ddz.mp4 “ container=”b7blbp0bc7m” subtitle=” “ poster=” “] [/video]
OpenGL 着色器编译
一、基本了解
GLSL: OpenGL Shading language
GLSL着色器程序通常包含:
- 版本声明:#version 330 core
- 输入/输出变量
- 主函数:void main() { … }
二、数据类型
2.1、基本类型:
- float:浮点数
- int:整数
- bool:布尔值
- void:无返回值
2.2、容器类型:
- vecn:vec2, vec3, vec4:浮点向量(2/3/4分量)
- ivecn: ivec2, ivec3, ivec4:整数向量
- bvecn: bvec2, bvec3, bvec4:布尔向量
后面的n表示几个的意思,如ivecn,后面的n表示有n个正数类型
2.3、矩阵类型:
matn: mat2, mat3, mat4
分别表示:2x2, 3x3, 4x4矩阵
2.4、变量修饰符
- in:输入变量(顶点着色器从应用程序接收数据)
- out:输出变量(传递到下一个着色阶段)
- uniform:从应用程序传入的全局常量
- layout(location = X):指定变量布局和位置
2.5、内置变量
顶点着色器:
gl_Position:输出顶点位置
片段着色器:
gl_FragCoord:片段坐标
输出通常自定义,如out vec4 FragColor
使用示例:
- 顶点着色器
1 |
|
layout(location = 0):显式指定顶点属性的位置索引,将着色器中的输入变量与OpenGL中的顶点属性绑定起来。一般来说,一个属性对应一个layout
OpenGL使用位置索引(location)来标识顶点属性。每个顶点属性(如位置、颜色、法线等)都需要一个唯一的索引值。
- X 是一个整数,表示顶点属性的位置索引
- 通过显式指定位置索引,可以避免OpenGL自动分配索引时的混淆,并确保应用程序和着色器之间的绑定一致。
aPos 是一个输入变量,表示顶点的三维位置。layout(location = 0) 将 aPos 绑定到位置索引 0。
我们在这里将location指定为0,那么在代码层面
1 | glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)0); |
glVertexAttribPointer 的第一个参数 0 对应 GLSL 中的 layout(location = 0)。表示顶点缓冲区中的数据将被传递到 GLSL 中的 aPos 变量。
多属性场景,前三个表示坐标,后三个表示颜色
1 | //顶点着色器 |
由于glVertexAttribPointer和glEnableVertexAttribArray这样指定容易出现问题,所以可以通过 glBindAttribLocation 或 glGetAttribLocation 手动查询和绑定位置索引。防止出错
1 | // 查询着色器中的位置属性 |
- 片段着色器
1 |
|
注意,传递参数时,需要确保类型和名字一致!!!,如顶点着色器传出的vertexColor要与片段着色器接收的vertexColor名字一致,都要叫做vertexColor,同时类型也需要一致,均为vec4
三、 常用函数
- 数学函数:sin, cos, pow, sqrt, mix, clamp
- 向量操作:点积.,叉积cross()
- 纹理采样:texture(sampler, texCoord)
四、uniform使用示例
通过定时器+uniform,将图形每隔1秒向右移动
- 顶点着色器
1 |
|
- 片段着色器
1 |
|
- moreAttributes.cpp
1 |
|
- moreAttributes.h
1 |
|
- main.cpp
1 |
|
QOpenGLShaderProgram
OpenGL默认设置着色器很繁琐,编译源码使用字符串硬编码的方式容易出错,如下面这种写法
1 | // 顶点着色器源码 |
为了解决这个问题,可以使用Qt封装好的OpenGLShaderProgram和资源文件处理,相关代码如下
- shape.vertex
1 |
|
- shape.fragment
1 |
|
示例:
1 | //声明 |
- QOpenGLShader::Vertex:创建一个顶点着色器
- QOpenGLShader::Fragment:创建一个片段着色器
- addShaderFromSourceFile:创建着色器,编译代码分别在**:/shaders/shape.vertex和:/shaders/shape.fragment**
opengl基本概念与使用
1、VBO
Vertex Buffer Object (VBO) 是 OpenGL 中用于存储顶点数据的缓冲区对象,是一块驻留在 GPU 高速内存中的数据块。
1.1、内存管理角度
- VBO 本质上是 GPU 内存上的一段线性空间
- 通过 glGenBuffers 创建并获取唯一标识符
- 通过 glBindBuffer 激活特定 VBO
- 通过 glBufferData 将数据从 CPU 传输到 GPU
1.2、数据传输流程
1 | // 1. 生成缓冲区对象 |
1.3、数据布局
- VBO 中的数据是原始字节序列
- 需要通过 glVertexAttribPointer 告诉 GPU 如何解释这些字节
1 | // 配置顶点属性(位置属性) |
1.4、优化策略
- GL_STATIC_DRAW:数据几乎不会改变
- GL_DYNAMIC_DRAW:数据经常改变
- GL_STREAM_DRAW:每次绘制都会改变
2、VAO
Vertex Array Object (VAO) 是一个状态容器,它保存了一组顶点数据配置的完整状态。
2.1、状态封装
- VAO 不存储实际顶点数据
- 它记录了与顶点处理相关的所有状态设置
- 包括顶点属性配置、VBO 绑定和 EBO 绑定
2.2、工作流程
1 | // 1. 创建VAO |
2.3、状态恢复
调用 glBindVertexArray(vao) 时:
- 所有启用/禁用的顶点属性 (glEnableVertexAttribArray/glDisableVertexAttribArray)
- 所有顶点属性指针配置 (glVertexAttribPointer)
- 当前绑定的 ARRAY_BUFFER (VBO绑定)
- 当前绑定的 ELEMENT_ARRAY_BUFFER (EBO绑定)
具体到代码
在 paintGL() 中调用 glBindVertexArray(VAO) 时:
- OpenGL 将 VAO 设置为当前活动的顶点数组对象
- 恢复 VAO 记录的所有状态,包括:
- 启用顶点属性 0(通过之前的 glEnableVertexAttribArray(0) 设置)
- 恢复顶点属性指针配置(通过之前的 glVertexAttribPointer 设置)
- 恢复 EBO 绑定(自动绑定 EBO,这就是为什么不需要在 paintGL() 中重新绑定 EBO)
- 这样,一行代码 glBindVertexArray(VAO) 就等效于以下多行代码:
1 | // 以下全部操作被 glBindVertexArray(VAO) 一行代码替代 |
3、EBO
EBO(也称为 Index Buffer Object,IBO)是 OpenGL 中用于存储顶点索引的缓冲区对象。它的主要目的是优化渲染性能,通过重用顶点数据来减少内存使用和数据传输。
3.1、EBO 工作原理
1、索引渲染的基本概念:
没有索引的情况下,如果绘制一个正方形,需要定义 6 个顶点(两个三角形),而很多顶点会重复。使用索引时,只需要 4 个顶点加上 6 个索引值。
2、 EBO 工作流程:
1 | // 定义顶点数据(存储在VBO中) |
3.EBO 的生成和绑定:
1 | // 生成 EBO |
4、使用 EBO 进行渲染:
1 | glDrawElements(GL_LINES, 8, GL_UNSIGNED_INT, NULL); |
- GL_LINES: 绘制模式,表示绘制线段
- 8: 索引数量,因为要画 4 条线(正方形的边),每条线需要 2 个索引
- GL_UNSIGNED_INT: 索引数据的类型
- NULL: 索引数组的起始位置偏移量,NULL 表示从头开始
- 在渲染时使用 glDrawElements 而不是 glDrawArrays,这样 GPU 会按照索引数组中指定的顺序读取顶点并渲染
3.2、EBO与VBO的关系
- 数据传输流程
1 | // 定义顶点数据(存储在VBO中) |
VBO和EBO都是存储在GPU内存中的缓冲区对象,当绘制调用发生时,GPU直接从这些缓冲区读取数据,无需从CPU内存传输
- 渲染流程:
1 | // 使用索引绘制 |
glDrawElements 的工作方式:
- 查找当前绑定的 EBO 中的索引
- 根据索引在当前绑定的 VBO 中获取对应的顶点数据,比如索引值”0”指向VBO中的第一个顶点(0.5f, 0.5f, 0.0f)
- 使用这些顶点数据进行渲染
EBO和VBO的关系就像"指挥"和"演员",EBO告诉GPU应该按什么顺序使用VBO中的哪些顶点来绘制图形。EBO 依赖于 VBO,单独的 EBO 没有意义,EBO 中的索引值引用的是 VBO 中的顶点位置
不使用EBO时:glDrawArrays()(按顺序使用VBO中的顶点)使用EBO时:glDrawElements()(按EBO中的索引顺序使用VBO中的顶点)
3.3、EBO 与 VAO 的关系
VAO (Vertex Array Object) 在EBO和VBO的关系中扮演”记录员“角色,当 VAO 被绑定时,随后绑定的 EBO 会被”记住”。
1 | // 绑定VAO开始记录 |
关键点:
1. VAO会记住VBO绑定和顶点属性配置
2. VAO会特殊记住EBO的绑定状态(这是VBO和EBO的一个重要区别)
3. 渲染时只需调用 **glBindVertexArray(VAO)**绑定VAO,不需要再次绑定VBO和EBO
4、着色器
4.1、顶点着色器
顶点着色器是渲染管线的第一个可编程阶段,负责处理每一个顶点。
4.1.1、工作原理
输入:
- 原始顶点数据(从 VBO 中获取)
- 顶点属性(位置、颜色、法线、纹理坐标等)
- 变换矩阵(模型、视图、投影等)
处理流程:
- 对每个顶点分别执行一次
- 至少需要计算顶点的裁剪空间坐标(gl_Position)
- 可以计算并传递其他数据给后续阶段
输出:
- 必须:裁剪空间中的位置(gl_Position)
- 可选:传递给片段着色器的数据(颜色、纹理坐标等)
具体到代码:
1 |
|
- version 330 core:指定 GLSL 版本 3.3,使用核心模式
- layout (location = 0) in vec3 aPos:声明一个输入顶点属性,位于位置 0,类型为 vec3
- gl_Position = vec4(aPos.x, aPos.y, aPos.z, 1.0):设置顶点的裁剪空间坐标
这个顶点着色器非常简单,仅将输入顶点位置直接传递到裁剪空间,没有应用任何变换(如模型视图投影变换)
4.2、片段着色器
片段着色器是渲染管线的最后一个可编程阶段,负责计算每个片段(可理解为潜在的像素)的最终颜色。
4.2.1、工作原理
输入:
- 光栅化阶段生成的片段
- 由顶点着色器传递的插值数据
- 纹理、uniform 变量等
处理流程:
- 对每个片段分别执行一次
- 计算片段的最终颜色
- 可以进行纹理采样、光照计算、特效处理等
输出:
- 片段的颜色值(通常写入到帧缓冲区)
- 可选:深度值、模板值等
具体到代码
1 |
|
- version 330 core:指定 GLSL 版本 3.3,使用核心模式
- out vec4 FragColor:声明一个输出变量,类型为 vec4,表示片段的颜色
- FragColor = vec4(0.0, 0.7, 1.0, 0.8):设置片段的颜色为淡蓝色,带有 80% 的不透明度
这个片段着色器非常简单,它为所有片段分配相同的淡蓝色。
4.3、着色器创建
1 | // ---- 2. 创建着色器程序 ---- |
4.4、着色器与VBO关系
1 | glGenBuffers(1, &VBO); |
此时数据已在 GPU 内存中,但着色器仍然不知道如何解释这些数据。
顶点属性配置 - 关键连接点
1 | glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)0); |
- 0:指定我们配置的是位置为 0 的顶点属性,对应着色器中的 layout (location = 0) in vec3 aPos
- 3:每个顶点属性由 3 个值组成(x, y, z 坐标),对应 vec3 类型
- GL_FLOAT:数据类型为浮点数
- GL_FALSE:不进行标准化
- 3 * sizeof(float):步长,下一个顶点的相同属性相隔多少字节
- (void)0*:该属性在每个顶点数据中的偏移量
这个调用的含义是:"告诉 GPU,将 VBO 中每隔 12 个字节(3个float)的 3 个浮点数解释为位置属性,并连接到着色器的 location 0 输入"。
4.5、着色器使用VBO
发出绘制命令,触发顶点着色器和片段着色器的执行:
1 | glUseProgram(shaderProgram); // 激活着色器程序 |
当顶点着色器执行时:
1. GPU 硬件从当前 VBO 读取一组顶点数据
2. 根据 glVertexAttribPointer 的配置,确定哪些字节对应哪个属性
3. 将这些字节转换为着色器中声明的相应类型(如 vec3)
4. 将转换后的值赋给着色器中的对应输入变量(如 aPos)
5. 顶点着色器代码运行,使用这些输入变量
4.6、多个顶点属性的情况
如果顶点有多个属性,流程会更复杂:
1 | // 顶点数据包含位置和颜色 |
- 第一个 glVertexAttribPointer 告诉 OpenGL 如何解析位置数据:步长为 6 个浮点数,偏移量为 0
- 第二个 glVertexAttribPointer 告诉 OpenGL 如何解析颜色数据:步长为 6 个浮点数,偏移量为 3 个浮点数
- VAO 会记录这两个属性的配置
4.7、大致流程
CPU上的顶点数据 → VBO → 顶点属性配置 → VAO记录 → 着色器接收 → 渲染输出
关键点:
1. glBufferData:CPU数据 → GPU内存
2. glVertexAttribPointer:原始字节 → 有意义的顶点属性
3. glEnableVertexAttribArray:启用该属性以便着色器访问
4. layout (location = X) in TYPE name:在着色器中声明输入变量
5. glBindVertexArray:一次性恢复所有状态配置
6. glUseProgram:指定使用哪个着色器程序
5、示例
使用到的组件:core;gui;widgets;opengl;openglwidgets;
- main.cpp
1 |
|
- OpenGLTest.h
1 |
|
- OpenGLTest.cpp
1 |
|
6、存在的问题
在上述示例用,如果将initBufferObject修改为如下写法就无法绘制图片
1 | void OpenGLTest::initBufferObject() |
一直不明白为什么,在drawTriangle和drawQuads函数中有注释部分的代码,但为什么无法绘制图片呢?为什么需要在初始化时就需要完成全部绑定?移到后面再绑定为什么不行?
当然,如果改为上述代码,drawTriangle和drawQuads函数需要加上如下代码
1 | glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)0); |
7、解决方案
发现觉得方案了!!!
原因是:在 Qt 中,如果不在标准的 initializeGL(), paintGL(), 或 resizeGL() 方法中执行 OpenGL 操作时(比如在 drawTriangle() 和 drawQuads() 中),Qt 不会自动管理 OpenGL 上下文。
所以我们需要手动管理OpenGL的上下文环境!!!需要用到两个函数:makeCurrent()和doneCurrent()
所以需要在initBufferObject,initShader,~OpenGLTest,drawTriangle和drawQuads等地方手动设置makeCurrent() 和doneCurrent(),将opengl操作的代码放在这两个函数中间
修改后的完整代码如下:
1 |
|
vs2022编码问题
1、warning C4819
解决方案:
在cmake文件中添加,必须位于 add_executable 之前
1 | add_compile_options("$<$<C_COMPILER_ID:MSVC>:/utf-8>") |
2、warning C4828
一、全局修改
工具>选项>环境>文档>使用特定编码保存文件,以后创建的文件就是以你指定的编码格式保存,注意是以后创建的,之前创建的需要手动修改

二、手动修改
工具>自定义>命令>文件>添加命令>高级保存选项,这里我选择放在文件,你也可以选择放在别的地方


可以通过上移和下移 调整位置,调整完位置后就会在指定位置出现这个选项了

如果为灰色,那是因为没有选择文件,在需要修改编码文件的编辑界面点击一下,就能点击了

这样就能修改文件编码了,挺麻烦的,需要一个一个修改

使用gprof和perf优化程序
一、gprof
- 测试用例
1 |
|
- 生成分析:
1 | g++ -pg gprof.cpp -o test |

关键参数:
- %time:该函数(包括其调用的子函数)占总程序运行时间的百分比。百分比越高的函数越值得优先优化。
- cumulative seconds:该函数及其所有子函数的总耗时
- self seconds:函数自身代码的直接耗时(不包含子函数的耗时)。若
self seconds高,说明函数内部逻辑复杂或计算密集。 - calls:函数在程序运行期间被调用的总次数。
- self ms/call:单次调用该函数自身的平均耗时(不包括子函数),衡量函数单次执行的效率,适用于优化高频调用的函数。
- total ms/call:单次调用该函数及其所有子函数的平均耗时。反映函数及其子函数的整体开销,用于分析调用链的总体成本。
- name:函数在代码中的名称(或符号)
通过 %time 和 cumulative seconds 找到耗时最长的代码路径。优先优化 %time 高且 self seconds 大的函数,或高频调用(calls 多)但 self ms/call 高的函数。
如图中所示:
matrix_multiply():占总执行时间的42.86%,被调用510次,每次调用花费约0.24毫秒std::vector<std::vector<double>, std::allocator<...>>相关操作:约占17.86%的时间create_matrix(int, double):占10.71%的时间,被调用30次,每次调用约1毫秒
优化建议:
- 高性能线性代数库替代自定义的
matrix_multiply create_matrix函数被调用次数不多但耗时较高,检查是否可以重用矩阵而非频繁创建- 避免使用嵌套
std::vector表示矩阵,会导致内存碎片和缓存不友好,使用专门的矩阵类或使用连续内存布局
二、perf
2.1、安装perf
1 | sudo apt install linux-tools-common linux-tools-generic linux-tools-`uname -r` |
2.2、使用
1 | g++ -g pref.cpp -o app |
如果遇到如下问题:
1 | Error: |
可以使用如下方法:
1 | sudo sh -c 'echo -1 > /proc/sys/kernel/perf_event_paranoid' |
redis常用命令
1. Redis服务器和客户端命令
redis-server
- 作用:启动Redis服务器。
- 返回值:无直接返回值,启动成功后进入运行状态。
- 示例:
1
2
3redis-server # 使用默认配置启动
redis-server /etc/redis/redis.conf # 指定配置文件启动
redis-server --port 6380 # 指定端口启动 - 注意事项:可在后台运行,使用
--daemonize yes参数,避免阻塞终端。 - 推荐使用:部署Redis服务时使用,确保配置文件路径正确。
redis-cli
- 作用:启动Redis命令行客户端,与服务器交互。
- 返回值:无直接返回值,进入交互模式。
- 示例:
1
2
3redis-cli # 连接本地默认服务器127.0.0.1:6379
redis-cli -h 192.168.1.100 -p 6380 # 连接指定主机和端口
redis-cli -a mypassword # 使用密码连接 - 注意事项:确保服务器已启动,默认连接本地6379端口。
- 推荐使用:调试或手动操作Redis时使用。
2. 通用命令
这些命令适用于所有键,不限定特定数据类型,主要用于管理键的元信息(如存在性、类型、过期时间等)。
keys
作用:查找匹配模式的键。
返回值:匹配的键列表,空列表表示无匹配键。
示例:
1
2
3keys * # 返回所有键,如 ["key1", "key2", "user:1"]
keys user:* # 返回以“user:”开头的键,如 ["user:1", "user:2"]
keys abc # 返回精确匹配“abc”的键,如 ["abc"]注意事项:生产环境慎用,会扫描整个键空间,影响性能。
推荐使用:调试或小规模数据时使用。
替代命令:
- 命令:
SCAN - 作用:逐步扫描键空间,避免性能问题。
- 示例:
SCAN 0 MATCH user:* COUNT 10 - 说明:更适合大数据量场景。
- 命令:
type
- 作用:返回键的数据类型。
- 返回值:
string,list,set,zset,hash,none(键不存在)。 - 示例:
1
2
3
4
5set mykey "hello"
type mykey # 返回 "string"
lpush mylist 1
type mylist # 返回 "list"
type nonexistent # 返回 "none" - 注意事项:仅返回类型,不涉及值。
- 推荐使用:检查键类型以避免操作错误。
exists
- 作用:检查键是否存在。
- 返回值:
1:存在。0:不存在。
- 示例:
1
2
3set mykey "hello"
exists mykey # 返回 1
exists nonexistent # 返回 0 - 注意事项:性能开销低。
- 推荐使用:在操作键前验证其存在性。
del
- 作用:删除一个或多个键。
- 返回值:删除的键数量。
- 示例:
1
2
3
4
5set key1 "v1"
set key2 "v2"
del key1 # 返回 1
del key2 key3 # 返回 1(key3不存在)
del nonexistent # 返回 0 - 注意事项:键不存在时不报错,返回0。
- 推荐使用:清理无用数据。
expire
- 作用:设置键的过期时间(单位:秒)。
- 返回值:
1:设置成功。0:键不存在或无法设置。
- 示例:
1
2
3set mykey "hello"
expire mykey 60 # 返回 1,60秒后过期
expire nonexistent 10 # 返回 0 - 注意事项:覆盖原有过期时间。
- 推荐使用:实现临时数据存储。
ttl
- 作用:返回键的剩余生存时间(单位:秒)。
- 返回值:
- 正整数:剩余秒数。
-1:无过期时间。-2:键不存在。
- 示例:
1
2
3
4
5
6set mykey "hello"
expire mykey 60
ttl mykey # 返回 60(或稍少)
set permkey "hi"
ttl permkey # 返回 -1
ttl nonexistent # 返回 -2 - 注意事项:常与
expire配合使用。 - 推荐使用:检查键的有效期。
persist
- 作用:移除键的过期时间,使其永久存在。
- 返回值:
1:成功移除。0:键不存在或无过期时间。
- 示例:
1
2
3
4set mykey "hello"
expire mykey 60
persist mykey # 返回 1
persist permkey # 返回 0(无过期时间) - 注意事项:对无过期时间的键无影响。
- 推荐使用:将临时键转为永久键。
rename
- 作用:重命名键。
- 返回值:
OK:成功。- 错误:键不存在。
- 示例:
1
2
3set oldkey "value"
rename oldkey newkey # 返回 "OK",oldkey变为newkey
get newkey # 返回 "value" - 注意事项:若newkey已存在,会被覆盖。
- 推荐使用:调整键名时使用。
3. 字符串(String)命令
字符串是Redis最基本的数据类型,可存储文本、数字或二进制数据,适合简单的键值对操作。
set
- 作用:设置键的值。
- 返回值:
OK。 - 示例:
1
2
3set mykey "hello" # 返回 "OK"
set mykey "world" # 返回 "OK",覆盖旧值
set counter 100 # 返回 "OK",存储数字 - 注意事项:键存在时覆盖旧值。
- 推荐使用:存储简单数据。
get
- 作用:获取键的值。
- 返回值:
- 字符串值:键存在。
nil:键不存在。
- 示例:
1
2
3set mykey "hello"
get mykey # 返回 "hello"
get nonexistent # 返回nil - 注意事项:仅适用于字符串类型。
- 推荐使用:读取单个值。
mset
- 作用:同时设置多个键值对。
- 返回值:
OK。 - 示例:
1
2
3mset key1 "v1" key2 "v2" # 返回 "OK"
get key1 # 返回 "v1"
get key2 # 返回 "v2" - 注意事项:覆盖已有键的值。
- 推荐使用:批量设置提高效率。
mget
- 作用:同时获取多个键的值。
- 返回值:值列表,未找到的键返回
nil。 - 示例:
1
2mset key1 "v1" key2 "v2"
mget key1 key2 key3 # 返回 ["v1", "v2", nil] - 注意事项:返回的结果顺序与输入一致。
- 推荐使用:批量读取减少请求。
append
- 作用:将值追加到键的现有值后。
- 返回值:追加后字符串长度。
- 示例:
1
2
3
4set mykey "hello"
append mykey " world" # 返回 11
get mykey # 返回 "hello world"
append newkey "start" # 返回 5(键不存在时新建) - 注意事项:键不存在时等同于
set。 - 推荐使用:扩展字符串内容。
decr
- 作用:将键的整数值减1。
- 返回值:减1后的值。
- 示例:
1
2
3set counter 10
decr counter # 返回 9
decr newcounter # 返回 -1(键不存在时从0开始) - 注意事项:
- 键不存在:初始值0,减1后为-1。
- 非整数值:报错。
- 推荐使用:计数器递减。
incr
- 作用:将键的整数值加1。
- 返回值:加1后的值。
- 示例:
1
2
3set counter 10
incr counter # 返回 11
incr newcounter # 返回 1(键不存在时从0开始) - 注意事项:
- 键不存在:初始值0,加1后为1。
- 非整数值:报错。
- 推荐使用:计数器递增。
strlen
- 作用:返回键值的字符串长度。
- 返回值:
- 整数:长度。
0:键不存在。
- 示例:
1
2
3set mykey "hello"
strlen mykey # 返回 5
strlen nonexistent # 返回 0 - 注意事项:仅适用于字符串类型。
- 推荐使用:检查字符串长度。
setex
- 作用:设置键值并指定过期时间(单位:秒)。
- 返回值:
OK。 - 示例:
1
2
3setex mykey 10 "hello" # 返回 "OK",10秒后过期
get mykey # 返回 "hello"
ttl mykey # 返回 10(或稍少) - 注意事项:覆盖旧值和过期时间。
- 推荐使用:创建带过期时间的临时数据。
4. 列表(List)命令
列表是一个有序、可重复的元素集合,基于双向链表实现,适合队列或栈场景。
lpush
作用:从列表左侧(头部)插入元素。
返回值:插入后列表长度。
示例:
1
2
3lpush mylist "a" # 返回 1
lpush mylist "b" "c" # 返回 3
lrange mylist 0 -1 # 返回 ["c", "b", "a"]注意事项:键不存在时创建新列表。
推荐使用:实现栈或左侧队列。
lrange
- 作用:获取列表指定范围的元素。
- 返回值:元素列表。
- 示例:
1
2
3lpush mylist "a" "b" "c"
lrange mylist 0 1 # 返回 ["c", "b"]
lrange mylist 0 -1 # 返回 ["c", "b", "a"] - 注意事项:索引从0开始,-1表示末尾。
- 推荐使用:读取列表内容。
rpush
- 作用:从列表右侧(尾部)插入元素。
- 返回值:插入后列表长度。
- 示例:
1
2
3rpush mylist "a" # 返回 1
rpush mylist "b" "c" # 返回 3
lrange mylist 0 -1 # 返回 ["a", "b", "c"] - 注意事项:键不存在时创建新列表。
- 推荐使用:实现队列或右侧追加。
linsert
- 作用:在指定元素前后插入新元素。
- 返回值:
- 插入后长度:成功。
-1:指定元素不存在。
- 示例:
1
2
3rpush mylist "a" "b" "c"
linsert mylist BEFORE "b" "x" # 返回 4
lrange mylist 0 -1 # 返回 ["a", "x", "b", "c"] - 注意事项:需指定
BEFORE或AFTER。 - 推荐使用:精确插入元素。
lindex
- 作用:获取指定索引的元素。
- 返回值:
- 元素值:存在。
nil:索引超出范围或键不存在。
- 示例:
1
2
3rpush mylist "a" "b" "c"
lindex mylist 1 # 返回 "b"
lindex mylist 10 # 返回 (nil) - 注意事项:索引从0开始。
- 推荐使用:访问特定位置元素。
llen
- 作用:返回列表长度。
- 返回值:
- 整数:长度。
0:键不存在。
- 示例:
1
2
3rpush mylist "a" "b"
llen mylist # 返回 2
llen nonexistent # 返回 0 - 注意事项:性能高效。
- 推荐使用:检查列表大小。
lset
作用:设置指定索引的值。
返回值:
OK:成功。- 错误:索引超范围或键不存在。
示例:
1
2
3rpush mylist "a" "b" "c"
lset mylist 1 "x" # 返回 "OK"
lrange mylist 0 -1 # 返回 ["a", "x", "c"]注意事项:索引必须有效。
推荐使用:修改列表元素。
lrem
- 作用:移除指定数量的匹配元素。
- 返回值:移除的元素数量。
- 示例:
1
2
3rpush mylist "a" "b" "a" "c"
lrem mylist 2 "a" # 返回 2
lrange mylist 0 -1 # 返回 ["b", "c"] - 注意事项:count为0时移除所有匹配。
- 推荐使用:清理重复元素。
5. 集合(Set)命令
集合是无序、不重复的元素集合,适合成员关系检查和集合运算。
sadd
作用:向集合添加元素。
返回值:成功添加的元素数量。
示例:
1
2sadd myset "a" # 返回 1
sadd myset "b" "a" # 返回 1("a"已存在)注意事项:重复元素会被忽略。
推荐使用:添加唯一元素。
smembers
作用:返回集合所有元素。
返回值:元素列表。
示例:
1
2sadd myset "a" "b" "c"
smembers myset # 返回 ["a", "b", "c"]注意事项:无序输出。
推荐使用:查看集合内容。
sinter
- 作用:返回多个集合的交集。
- 返回值:交集元素列表。
- 示例:
1
2
3sadd set1 "a" "b" "c"
sadd set2 "b" "c" "d"
sinter set1 set2 # 返回 ["b", "c"] - 注意事项:至少两个集合。
- 推荐使用:查找共同元素。
sdiff
作用:返回第一个集合与第二个集合的差集,但只包含第一个集合的值。
返回值:差集元素列表。
示例:
1
2
3sadd set1 "a" "b" "c"
sadd set2 "b" "d"
sdiff set1 set2 # 返回 ["a", "c"]注意事项:顺序影响结果。
推荐使用:查找独有元素。
sunion
- 作用:返回多个集合的并集。
- 返回值:并集元素列表。
- 示例:
1
2
3sadd set1 "a" "b"
sadd set2 "b" "c"
sunion set1 set2 # 返回 ["a", "b", "c"] - 注意事项:自动去重。
- 推荐使用:合并集合。
spop
- 作用:随机移除并返回一个元素。
- 返回值:移除的元素。
- 示例:
1
2
3sadd myset "a" "b" "c"
spop myset # 返回 "b"(随机)
smembers myset # 返回 ["a", "c"] - 注意事项:集合为空时返回
nil。 - 推荐使用:随机抽取元素。
srem
- 作用:移除集合中的指定元素。
- 返回值:移除的元素数量。
- 示例:
1
2sadd myset "a" "b" "c"
srem myset "b" "d" # 返回 1("d"不存在) - 注意事项:不存在的元素忽略。
- 推荐使用:删除特定元素。
sismember
- 作用:检查元素是否在集合中。
- 返回值:
1:存在。0:不存在。
- 示例:
1
2
3sadd myset "a" "b"
sismember myset "a" # 返回 1
sismember myset "c" # 返回 0 - 注意事项:高效查询。
- 推荐使用:验证成员关系。
srandmember
- 作用:随机返回集合中的元素(不移除)。
- 返回值:随机元素。
- 示例:
1
2sadd myset "a" "b" "c"
srandmember myset # 返回 "a"(随机) - 注意事项:可指定返回数量。
- 推荐使用:随机选择元素。
smove
- 作用:将元素从一个集合移动到另一个集合。
- 返回值:
1:成功。0:元素不存在。
- 示例:
1
2
3
4sadd set1 "a" "b"
sadd set2 "c"
smove set1 set2 "a" # 返回 1
smembers set2 # 返回 ["c", "a"] - 注意事项:源集合会减少元素。
- 推荐使用:元素迁移。
6. 有序集合(Sorted Set)命令
有序集合是有序、不重复的元素集合,每个元素关联一个分数,适合 排行榜或优先级队列。
zadd
作用:添加元素及其分数。
返回值:新增的元素数量。
示例:
1
2zadd myset 1 "a" # 返回 1
zadd myset 2 "b" 1 "a" # 返回 1("a"已存在)注意事项:重复元素更新分数。
推荐使用:构建排行榜。
zrevrange
- 作用:按分数从高到低返回指定范围元素。
- 返回值:元素列表。
- 示例:
1
2zadd myset 1 "a" 2 "b" 3 "c"
zrevrange myset 0 1 # 返回 ["c", "b"] - 注意事项:索引从0开始。
- 推荐使用:获取高分元素。
zcount
- 作用:统计分数范围内的元素数量。
- 返回值:数量。
- 示例:
1
2zadd myset 1 "a" 2 "b" 3 "c"
zcount myset 1 2 # 返回 2 - 注意事项:包含边界值。
- 推荐使用:统计符合条件的元素。
zrank
- 作用:返回元素从低到高的排名。
- 返回值:
- 整数:排名(从0开始)。
nil:元素不存在。
- 示例:
1
2zadd myset 1 "a" 2 "b" 3 "c"
zrank myset "b" # 返回 1 - 注意事项:分数低的排前面。
- 推荐使用:查询排名。
zrevrank
- 作用:返回元素从高到低的排名。
- 返回值:
- 整数:排名。
nil:元素不存在。
- 示例:
1
2zadd myset 1 "a" 2 "b" 3 "c"
zrevrank myset "b" # 返回 1 - 注意事项:分数高的排前面。
- 推荐使用:查询逆序排名。
zscore
- 作用:返回元素的分数。
- 返回值:
- 分数值:存在。
nil:不存在。
- 示例:
1
2zadd myset 1 "a" 2 "b"
zscore myset "a" # 返回 "1" - 注意事项:返回字符串格式。
- 推荐使用:查询元素分数。
zrem
- 作用:移除指定元素。
- 返回值:移除的元素数量。
- 示例:
1
2zadd myset 1 "a" 2 "b"
zrem myset "a" "c" # 返回 1("c"不存在) - 注意事项:不存在的元素忽略。
- 推荐使用:删除元素。
7. 哈希(Hash)命令
哈希是一个键值对集合,适合存储对象,字段名唯一且内存占用少。
hset
作用:设置哈希字段的值。
返回值:
1:新增字段。0:更新字段。
示例:
1
2hset myhash name "Alice" # 返回 1
hset myhash name "Bob" # 返回 0注意事项:字段存在时覆盖。
推荐使用:存储对象属性。
新功能说明:自Redis 4.0起,
hset支持设置多个字段值。- 示例:
hset myhash name "Alice" age "25"
- 示例:
hmset
- 作用:同时设置多个字段值。
- 返回值:
OK。 - 示例:
1
hmset myhash name "Alice" age "25" # 返回 "OK"
- 注意事项:Redis 4.0+建议用
hset替代。 - 推荐使用:批量设置字段。
- 替代命令:
- 命令:
hset - 作用:设置单个或多个字段值。
- 示例:
hset myhash name "Alice" age "25" - 说明:功能更灵活,替代
hmset。
- 命令:
hget
- 作用:获取字段值。
- 返回值:
- 值:存在。
nil:不存在。
- 示例:
1
2
3hset myhash name "Alice"
hget myhash name # 返回 "Alice"
hget myhash age # 返回 (nil) - 注意事项:仅适用于哈希。
- 推荐使用:读取单个字段。
hmget
- 作用:获取多个字段值。
- 返回值:值列表。
- 示例:
1
2hmset myhash name "Alice" age "25"
hmget myhash name age # 返回 ["Alice", "25"] - 注意事项:不存在的字段返回
nil。 - 推荐使用:批量读取字段。
hgetall
- 作用:返回所有字段和值。
- 返回值:字段-值对列表。
- 示例:
1
2hmset myhash name "Alice" age "25"
hgetall myhash # 返回 ["name", "Alice", "age", "25"] - 注意事项:数据量大时性能较低。
- 推荐使用:查看哈希全部内容。
hkeys
- 作用:返回所有字段名。
- 返回值:字段列表。
- 示例:
1
2hmset myhash name "Alice" age "25"
hkeys myhash # 返回 ["name", "age"] - 注意事项:键不存在返回空列表。
- 推荐使用:获取字段名。
hvals
- 作用:返回所有字段值。
- 返回值:值列表。
- 示例:
1
2hmset myhash name "Alice" age "25"
hvals myhash # 返回 ["Alice", "25"] - 注意事项:无字段名。
- 推荐使用:获取所有值。
hexists
作用:检查字段是否存在。
返回值:
1:存在。0:不存在。
示例:
1
2
3hset myhash name "Alice"
hexists myhash name # 返回 1
hexists myhash age # 返回 0注意事项:高效查询。
推荐使用:验证字段存在性。
hlen
- 作用:返回字段数量。
- 返回值:
- 整数:数量。
0:键不存在。
- 示例:
1
2hmset myhash name "Alice" age "25"
hlen myhash # 返回 2 - 注意事项:性能高效。
- 推荐使用:统计字段数。
hdel
- 作用:删除指定字段。
- 返回值:删除的字段数量。
- 示例:
1
2
3hmset myhash name "Alice" age "25"
hdel myhash name # 返回 1
hget myhash name # 返回 (nil) - 注意事项:不存在的字段忽略。
- 推荐使用:清理字段。
基于protobuf开发的rpc框架
RPC(Remote Procedure Call Protocol)远程过程调用协议,过程示意图
一、提供方配置
1.1、生成服务对象
要提供RPC服务,需要在proto中添加service信息,protoc会为每个service生成对应的C++类,包含虚函数,用户需要继承并实现这些函数。但这些生成的代码并不处理实际的网络通信,只是提供了一个框架,需要用户自己填充具体的逻辑,或者结合其他RPC库使用。
1 | syntax = "proto3"; |
1.2、提取服务
protobuf会为每一个service生成对应的抽象描述,具体实现需要我们继承这些类并实现对应的方法,然后通过protobuf内部实现的多态进行调用。
获取服务对象的描述信息,描述中包含service的
名字,方法数量以及方法的抽象描述,将这些信息封装到map表中,用于处理服务和方法的寻找1
2
3
4
5const google::protobuf::ServiceDescriptor* pserviceDesc = service->GetDescriptor();
std::string service_name = pserviceDesc->name();//service名字
int methodCnt = pserviceDesc->method_count();//service方法数量
const google::protobuf::MethodDescriptor* pmethonDest = pserviceDesc->method(i);//方法的抽象描述
std::string method_name = pmethonDest->name();//方法的名字
1.3、启动RPC服务
现在存在一个问题,那就是通过RPC实现的分布式框架会很多RPC服务提供者,调用方是如何知道每一个服务的调用地址呢,总不能列一个静态配置文件,一个一个的罗列出来吧,这样维护成本太高了,每次添加或删除一个service服务,调用方都要修改配置文件并重新启动。服务方的进行修改时还需要修改调用方,这样的设计实在太糟糕了。
为了解决上述问题,zookeeper就出现了,根据观察者模式的思想,每一个提供方在启动时都在zookeeper中注册信息,调用方的所有调用,只需要发送给zookeeper,至于调用方的地址在哪,调用方都无需关心,一切都由zookeeper负责。这样,调用方就只需要关注zookeeper地址即可,服务方的修改也不会影响到调用方。

连接zookeeper服务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// 连接zkserver
void ZKClient::Start()
{
std::string host = MprpcApplication::GetInstance().getConfig().Load("zookeeperip");
std::string port = MprpcApplication::GetInstance().getConfig().Load("zookeeperport");
std::string connstr = host + ":" + port;
m_zhandle = zookeeper_init(connstr.c_str(), global_watcher, 30000, nullptr, nullptr, 0);
if (nullptr == m_zhandle)
{
perror("zookeeper_init");
exit(EXIT_FAILURE);
}
sem_t sem;
sem_init(&sem, 0, 0);
zoo_set_context(m_zhandle, &sem);
// 阻塞等待global_watcher函数被调用,在ZooKeeper连接成功建立解除阻塞
sem_wait(&sem);
}往zookeeper中注册服务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// 注册服务
for(auto &sp : m_serviceMap)
{
std::string service_path = "/" + sp.first;
// 0表示永久性节点
zkclient.Create(service_path.c_str(), nullptr, 0);
for(auto &mp : sp.second.m_methodMap)
{
std::string method_path = service_path + "/" + mp.first;
char method_path_buffer[128] = {0};
snprintf(method_path_buffer, sizeof(method_path_buffer), "%s:%d",ip.c_str(), port);
// ZOO_EPHEMERAL 表示创建临时节点
zkclient.Create(method_path.c_str(), method_path_buffer, strlen(method_path_buffer),ZOO_EPHEMERAL);
}
}最后,启动网络服务完成最后的RPC启动工作
1
2server.start();
m_eventLoop.loop();
二、RPC提供者实现细节
前面提到,protoc会为每个service生成对应的C++类,包含虚函数,用户需要继承并实现这些函数。
首先我们可以看见,FriendServiceRpc是protoc给我们自动生成的service类,我们可以看到它继承了google ::protobuf::Service
- 我们可以先看看google ::protobuf::Service的实现,我们可以看见,这是一个抽象类
1 | class PROTOBUF_EXPORT Service { |
- protobuf生成的服务类
FriendServiceRpc,这个类通过继承google ::protobuf::Service并重写CallMethod方法调用我们重写的函数GetFriendList
1 | class FriendServiceRpc : public ::PROTOBUF_NAMESPACE_ID::Service { |
- 我们自定义的服务类,用于继承并重写FriendServiceRpc中的虚函数
1 | class FriendService : public friendservice::FriendServiceRpc |
从上面我们可以大致看出,RPC服务提供者处理就是在服务端请求到达时,首先会将父类指针google::protobuf::Service*指向子类对象,这个子类对象实际上就是上面的class FriendService : public friendservice::FriendServiceRpc,也就是我们自己实现的类,再通过FriendService的CallMethod方法(由于没有重写,实际上是父类的CallMethod方法)调用我们重写的方法,至于怎么确定是哪个函数,这个由protobuf内部负责的,具体逻辑就是我们们看见的FriendServiceRpc重写的CallMethod方法,这个CallMethod会调用我们重写好的函数。

实际上,protobuf知道我们要调用哪个函数,是需要我们传递一些参数的,我们可以看到CallMethod的函数声明
1 | virtual void CallMethod(const MethodDescriptor* method, |
- method:就是对应调用方法的描述,
const google::protobuf::MethodDescriptor* method,通过这个描述,FriendServiceRpc就能知道要调用哪个方法。 - controller:通过这个RpcController类,我们可以查询返回数据时是否发生错误,并获得相关的RPC的信息,如错误的信息。
- request:包含方法的参数信息
- response: 包含服务提供者返回的响应消息
- done: 用于发送数据给客户端
1 | //request |
首先,我们首先要根据protobuf的数据格式约定,提取出调用方的调用信息
1 | //解析服务描述信息 |
然后查看服务和方法是否存在
1 | auto it = m_serviceMap.find(service_name); |
初始化request的参数数据
1 | google::protobuf::Message* request = service->GetRequestPrototype(method).New(); |
最后调用CallMethod方法
1 | service->CallMethod(method, nullptr, request, response, done); |
具体代码实现:
1 | void RpcProvider::onMessage(const muduo::net::TcpConnectionPtr& conn, |
三、调用方配置
使用姿势
1 | // 初始化框架 |
四、RPC调用者实现细节
protobuf不就会生成服务提供者相关的类,同样还会实现调用者相关的类
与提供者不同的是,调用的创建的父类对象是继承自FriendServiceRpc,也就是提供者的那个父类,每一个服务提供者的类都会生成一个对应的Stub类,调用方通过这个Stub类就能与提供方实现数据间相互处理。
1 | class FriendServiceRpc_Stub : public FriendServiceRpc { |
实际上,FriendServiceRpc_Stub 类并没有直接实现 CallMethod 方法,而是通过一个更精妙的设计来实现 RPC 调用。当我们查看 FriendServiceRpc_Stub 的构造函数时,可以发现它需要一个 RpcChannel 对象作为参数。这个 RpcChannel 类才是真正包含 CallMethod 方法的地方。这样表示着,调用方的所有操作,最终都会通过经过这个RpcChannel类并通过其CallMethod方法发出。 而 RpcChannel 本身是一个抽象类,只定义了这一个纯虚方法,这正是 Protocol Buffers 框架的精髓所在 - 它提供了接口定义,但将具体的网络通信实现留给了开发者。通过继承 RpcChannel 并重写其 CallMethod 方法,我们可以实现序列化和反序列化逻辑,添加额外的元数据(如超时设置、重试策略等)等。
1 | class PROTOBUF_EXPORT RpcChannel { |
具体的执行过程如下:
- 客户端通过Stub类调用对应的RPC接口,在这个接口中调用RpcChannel的CallMethod方法
1 | stub.GetFriendList(&controller, &getFriendListRequest, &getFriendListResponse, nullptr); |
- RpcChannel的CallMethod方法实际上调用的是我们重写的方法,用于封装并发送的数据
1 | class MprpcChannel : public google::protobuf::RpcChannel |
总体来说,调用方只需要继承RpcChannel并重写其CallMethod方法,调用方只需要提供对应的参数,调用的方法就能,就能通过CallMethod方法实现自动处理发送并处理RPC请求与响应,其余交给框架处理。
MySQL-主从复制
 主从复制:两个日志(
主从复制:两个日志(binlog二进制日志,relay log日志)和三个线程(master一个线程和slave两个线程)主库对外提高增删改查服务,从库根据二进制日志将数据同步到从库.
一、主从复制流程:两个日志(binlog/relay log)和三个线程(主库的转储线程和从库的IO线程与sql线程)
主库的更新操作写入binlog二进制日志中
master服务器创建一个binlog转储线程(
binlog dump process),将二进制日志内容发送到从服务器。可以通过show processlist;查看线程信息slave机器执行START SLAVE命令会在从服务器创建一个IO线程,接收master的
binary log并复制到其relay log中继日志。sql slave thread(sql从线程)处理该过程的最后一步,sql线程从中继日志中读取事件,并重放其中的事件而更新slave机器的数据,使其与master主库的数据一致。只要该线程与I/O线程保持一致,中继日志通常会位于os缓存中,所以中继日志的开销很小。
从数据库生成两个线程,一个是IO线程,用于将binlog日志写到relay log中,同时还会创建一个sql线程,用于读取relay log中的命令并重放到从数据库中,执行写操作,insert,update,delete等操作
二、主从复制作用:
- 数据备份:即使主库挂了,也可以通过mycat将请求映射到从库,继续对外服务
- 热备份:
- 通过主从复制,主库的数据会实时同步到从库,从库作为实时的备份库(热备份)可以随时切换。
- 如果主库发生故障,可以快速将从库提升为主库,继续提供服务,最大程度减少数据丢失和服务中断。
- 容灾:
- 在数据中心宕机或硬件故障的情况下,从库位于不同物理位置(例如异地机房),可用作容灾库,保证业务连续性。
- 高可用:
- 配合负载均衡工具(如 MyCat、HAProxy、Keepalived),当主库不可用时,可以自动切换到从库,提高系统的可用性。
- 热备份:
- 读写分离
- 操作由主库处理:
- 主库负责处理事务性较强、需要严格一致性的写操作(如
INSERT、UPDATE、DELETE等)。 - 写操作完成后,主库通过二进制日志(binlog)将更改同步到从库。
- 主库负责处理事务性较强、需要严格一致性的写操作(如
- 读操作由从库处理:
- 从库负责处理只读操作(如
SELECT查询)。 - 一个主库可以有多个从库(常见为 1 主多从架构),将大量的读请求分摊到多个从库中,减少主库的负载,提高整体读写效率。
- 从库负责处理只读操作(如
- 优点:
- 提高性能:减少主库压力,通过多个从库分担读取任务,支持更多并发读请求。
- 优化资源:主库的写性能和从库的读性能可以分别优化,避免资源浪费。
- 操作由主库处理:
三、主从复制的局限性与优化
限制
- 数据延迟:
- 主库的写操作通过 binlog 异步传输到从库,可能会有微小的同步延迟(尤其在网络较差或从库负载较高时)。
- 对于强一致性要求高的业务,需要额外设计机制。
- 从库只读:
- 在默认配置下,从库是只读的。如果在从库上进行写操作,可能导致数据不一致。
- 主库压力过大:
- 在写操作较多的情况下,主库压力仍然较大,可能需要结合分库分表进一步优化。
- 数据延迟:
优化
半同步复制:
从库在接收到 binlog 并写入中继日志后,才向主库确认,减少数据延迟和丢失的风险。
双主模式(主主复制):
- 两个主库相互同步,一方故障时另一方可以无缝接管,增强容灾能力。
分布式数据库:
- 配合分库分表和分布式数据库中间件(如 ShardingSphere、MyCat),实现更高效的负载均衡和扩展性。
总结
- 数据备份:
- 主从复制实现了实时的数据同步,提供热备份、容灾和高可用能力。
- 在主库故障时,从库可以接管服务,保证系统的持续运行。
- 读写分离:
- 主库负责写操作,从库负责读操作,合理分摊压力。
- 通过增加从库数量,可以线性扩展读性能,支持高并发场景。
四、配置主从复制
linux为主库,windows为从库
条件:
master和slave机器的信息
- master(Ubuntu 24):192.168.135.129
- slave : 10.157.219.148
需要保证master和slave之间的网络互通,并且保证3306端口是开放的
主库配置:
- Ubuntu 24 打开3306端口
1
2
3
4#允许所有请求
sudo ufw allow 3306
#只允许指定IP的请求
sudo ufw allow from <IP地址> to any port 3306- Ubuntu24 打开二进制日志,修改/etc/mysql/my.cnf文件
1
2
3
4
5[mysqld]
server-id=1#用于区分从库
expire_logs_days=7#二进制日志保存时间
log-bin=mysql-bin #开启二进制日志
binlog-do-db=mytest #指定同步的库名,如果不填写,默认是全局- 创建用于主从库通信的账号,只允许从库服务器登录
1
2
3CREATE USER 'mslave'@'192.168.135.1' IDENTIFIED BY '123456';
GRANT REPLICATION SLAVE ON *.* TO 'mslave'@'192.168.135.1';
FLUSH PRIVILEGES;这里没有填写windows的地址是因为Ubuntu24是运行在windows的虚拟机上面,使用的是NAT网络模式(如果使用桥接模式就没什么问题,直接写windows的地址),NAT模式会创建一个虚拟网卡,windows在与虚拟机中的linux服务器进行通信时,首先会将数据发送到192.168.135.1这个网关上,然后再转发到虚拟机中的linux服务器,所以虚拟机中的linux服务器接收来自windows的消息实际上全部都是从192.168.135.1这个网关转发过来的。所以这里填写192.168.135.1才能通过。

- 获取主库binlog的日志文件名和position位置
1
2
3
4
5
6
7
8
9mysql> show master status;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000001 | 1533| | | |
+------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
mysql>从库配置
修改配置文件,”C:\ProgramData\MySQL\MySQL Server 8.0\my.ini”
1
2
3
4[mysqld]
server-id=2
relay-log=relay-bin
log_bin=slave-bin然后在任务管理器中的服务中重启MySQL服务

登录mysql创建账户读取binlog同步数据,执行如下语句
1
2
3
4
5
6CHANGE MASTER TO MASTER_HOST='192.168.135.129',
MASTER_PORT=3306,
MASTER_USER='mslave',
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=1533;开启从库服务
1
start slave;
查看服务状态
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Connecting to source
Master_Host: 192.168.135.129
Master_User: mslave
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 885
Relay_Log_File: zjz-relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: Connecting
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 885
Relay_Log_Space: 157
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 2061
Last_IO_Error: Error connecting to source 'mslave@192.168.135.129:3306'. This was attempt 1/86400, with a delay of 60 seconds between attempts. Message: Authentication plugin 'caching_sha2_password' reported error: Authentication requires secure connection.
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 0
Master_UUID:
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Replica has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp: 241204 22:40:21
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
Master_public_key_path:
Get_master_public_key: 0
Network_Namespace:
1 row in set, 1 warning (0.00 sec)
mysql>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16mysql> show processlist;
+----+-----------------+-----------------+------+---------+------+----------------------------------------------------------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-----------------+-----------------+------+---------+------+----------------------------------------------------------+------------------+
| 5 | event_scheduler | localhost | NULL | Daemon | 510 | Waiting on empty queue | NULL |
| 8 | root | localhost:8068 | NULL | Query | 0 | init | show processlist |
| 9 | system user | connecting host | NULL | Connect | 175 | Connecting to source | NULL |
| 10 | system user | | NULL | Query | 175 | Replica has read all relay log; waiting for more updates | NULL |
| 11 | system user | | NULL | Connect | 175 | Waiting for an event from Coordinator | NULL |
| 12 | system user | | NULL | Connect | 175 | Waiting for an event from Coordinator | NULL |
| 13 | system user | | NULL | Connect | 175 | Waiting for an event from Coordinator | NULL |
| 14 | system user | | NULL | Connect | 175 | Waiting for an event from Coordinator | NULL |
+----+-----------------+-----------------+------+---------+------+----------------------------------------------------------+------------------+
8 rows in set, 1 warning (0.00 sec)
mysql>
错误排查:
问题1:
1
2Last_IO_Errno: 2061
Last_IO_Error: Error connecting to source 'mslave@192.168.135.129:3306'. This was attempt 1/86400, with a delay of 60 seconds between attempts. Message: Authentication plugin 'caching_sha2_password' reported error: Authentication requires secure connection.问题的原因是 MySQL 8.0 默认使用
caching_sha2_password作为认证插件,而从库在连接主库时未启用 SSL 或使用了不支持caching_sha2_password的连接方式。解决方案:
方法 1:修改用户的认证插件为
mysql_native_password在主库修改用户认证插件: 登录主库,执行以下命令:
1
2ALTER USER 'mslave'@'192.168.135.1' IDENTIFIED WITH 'mysql_native_password' BY '123456';
FLUSH PRIVILEGES;这会将用户
mslave的密码认证插件从caching_sha2_password改为mysql_native_password。mysql_native_password不要求使用 SSL 连接,可以解决当前问题。
重启从库同步: 在从库执行以下命令:
1
2STOP SLAVE;
START SLAVE;验证同步状态: 查看同步状态,确认是否正常:
1
SHOW SLAVE STATUS\G;
方法二:启用 SSL 连接(推荐),但没试过,使用方法一已经成功了
如果你希望继续使用
caching_sha2_password,则需要在主从之间启用 SSL 安全连接。在主库启用 SSL 支持: 编辑主库的配置文件(
my.cnf):1
2
3
4[mysqld]
ssl-ca=/path/to/ca-cert.pem
ssl-cert=/path/to/server-cert.pem
ssl-key=/path/to/server-key.pem重启主库服务:
1
sudo systemctl restart mysql
在从库启用 SSL 支持: 确保从库也配置了 SSL 并指定主库的证书。可以在
CHANGE MASTER TO命令中添加 SSL 参数:1
2
3
4
5
6
7
8
9
10CHANGE MASTER TO
MASTER_HOST='192.168.135.129',
MASTER_USER='mslave',
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=120,
MASTER_SSL=1,
MASTER_SSL_CA='/path/to/ca-cert.pem',
MASTER_SSL_CERT='/path/to/client-cert.pem',
MASTER_SSL_KEY='/path/to/client-key.pem';重启从库同步:
1
START SLAVE;
排查技巧:
在进行主从复制前,确保要同步的数据库,表名,表结构,数据库等在从库一定要实现创建!且必须要一模一样!否则可能会如下报错
1
Coordinator stopped because there were error(s) in the worker(s). The most recent failure being: Worker 1 failed executing transaction 'ANONYMOUS' at source log mysql-bin.000003, end_log_pos 2682. See error log and/or performance_schema.replication_applier_status_by_worker table for more details about this failure or others, if any.
经过排查发现,错误可能是从库中的表没创建,字符集不一致,varchar大小不够,类型不一致等问题导致的!事务出现错误
查看错误日志!这点很重要!在这里可以详细看见错误的信息1
select * from performance_schema.replication_applier_status_by_worker\G
1
2
3Worker 1 failed executing transaction 'ANONYMOUS' at source log mysql-bin.000003, end_log_pos 2974; Column 0 of table 'mytest.test' cannot be converted from type 'varchar(400(bytes))' to type 'varchar(300(bytes) utf8mb3)'
Worker 1 failed executing transaction 'ANONYMOUS' at source log mysql-bin.000003, end_log_pos 2682; Error executing row event: 'Table 'mytest.test' doesn't exist'例如上面第一个错误就是字符集和长度不一致导致的,从库使用了utf8mb3,主库使用了utf8mb4; 第二个错误就是从库的表没有创建!在开始主从复制前,我们需要配置与主库相同的库表环境!可以导出主库的二进制日志文件sql,确保环境一致!
网络相关

- 网络能否ping通
- 主库所在机器的3306端口是否正常 telnet xxxx 3306测试
- 查看主库的错误日志
- 查看地址等是否正确,是使用NAT网络还是桥接网络?NAT使用网关,桥接使用IP
MySQL-读写分离配置
读写分离就是在主服务器上修改,数据会同步到从服务器,从服务器只能提供读取数据,不能写入,实现备份的同时也实现了数据库性能的优化,以及提升了服务器安全。

使用读写分离,一般需要配合代理中间件MyCat,客户端将要执行的sql发送到MyCat,MyCat会根据sql的类型发送到不同的服务器上,如果是写操作,则发送到主服务器上,如果是读操作,则发送到从服务器上,已解决强耦合问题。
读写分离需要配合主从复制,以同步主从服务器的数据。
MyCat服务器:
- 一主一从
- 一主多从
- 多主多从
- 多主多从就是包含多个独立的主从环境,假如有A,B两套环境,A环境如上图所示,A 环境的一主多从结构独立于 B 环境,B环境也是如此,同时,A 环境的主服务器与 B 环境的主服务器之间配置为主从关系,假设A为主服务器,那么操作A时会将数据同步到B环境的主服务器,已达到数据同步的效果,当 A 环境出现故障时,B 环境可以迅速接替工作,提供高可用性和容灾能力。
一、读写分离配置
环境:
JDK环境:MyCat由java开发,需要JDK环境
1
java -version
查看环境,一般按照linux时已经自带了
查看root用户能否远程连接
1
2use mysql;
select user,host from user;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21mysql> use mysql;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select user,host from user;
+------------------+---------------+
| user | host |
+------------------+---------------+
| root | % |
| zhangsan | % |
| mslave | 192.168.135.1 |
| debian-sys-maint | localhost |
| mysql.infoschema | localhost |
| mysql.session | localhost |
| mysql.sys | localhost |
| root | localhost |
+------------------+---------------+
8 rows in set (0.00 sec)
mysql>添加root用户远程访问:
1
2
3CREATE USER 'root'@'ip_address' IDENTIFIED BY 'some_pass';
GRANT ALL PRIVILEGES ON *.* TO 'root'@'ip_address';
FLUSH PRIVILEGES;ip_address可以填写MyCat地址,也可以时MyCat地址
安装mycat
客户端默认端口:8066, 管理端端口:90661
tar -zxvf xxx.tar.gz
添加一个软连接到/usr/bin目录下,需要root权限
1
ln -s /home/zjz/Downloads/mycat/bin/mycat /usr/bin/mycat
配置:
server.xml配置MyCat账号信息,用于登录,1
2
3
4
5
6
7
8
9
10
11
12
13
14<user name="root">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>- password:登录密码,可自定义
- scemas:逻辑库,指定一个用户只能访问某些逻辑库,而不是 MyCat 中的所有库。配合 MyCat 的权限控制机制,可以为不同用户分配不同的库访问权限。 逻辑库与物理数据库的库表通过
schema.xml进行映射。用户通过 MyCat 访问逻辑库时,MyCat 会根据配置将请求路由到相应的物理库和表。
schema.xml配置逻辑库,这里配置的逻辑库名字要与在server.xml中配置的逻辑库名字一致,下面是一个多主多从配置1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
<mycat:schema xmlns:mycat="http://io.mycat/">
<!--配置逻辑数据库-->
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"></schema>
<!--存储节点-->
<dataNode name="dn1" dataHost="node1" database="mytest"/>
<!--数据库主机-->
<dataHost name="node1" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat> select test()</heartbeat>
<!--can have multi write hosts-->
<writeHost host="192.168.135.129" url="192.168.135.129:3306" user="root" password="123456">
<readHost host="10.157.219.148" url="10.157.219.148:3306" user="root" password="123456"/>
</writeHost>
<writeHost host="10.157.219.148" url="10.157.219.148:3306" user="root" password="123456"/>
</dataHost>
</mycat:schema>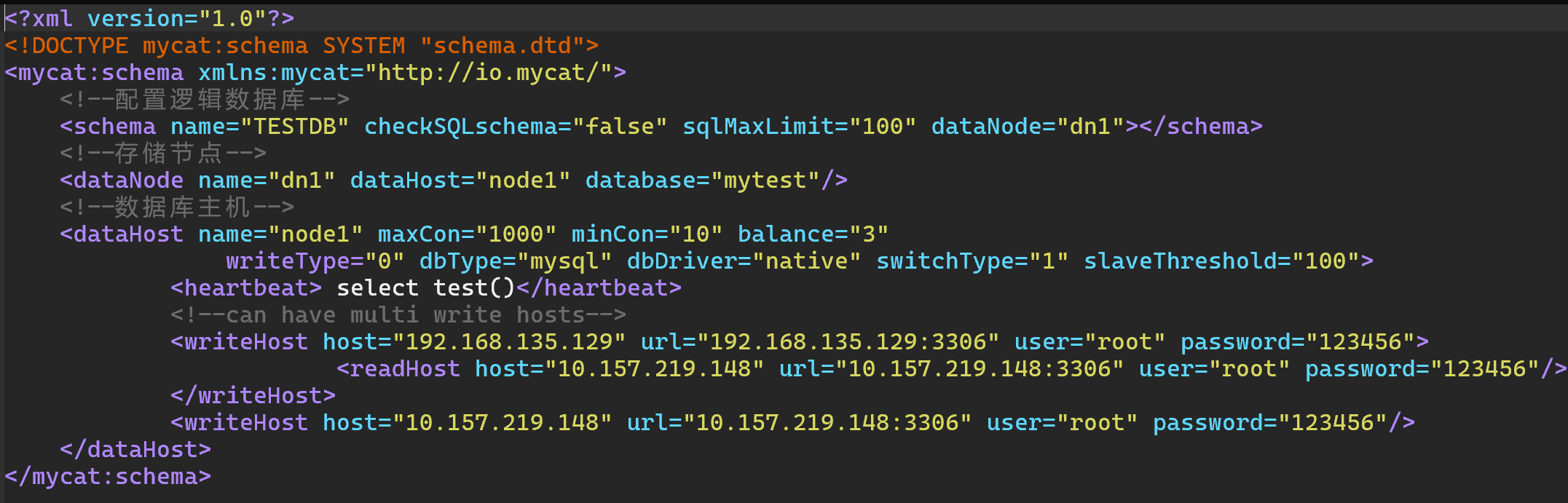
逻辑数据库配置 (
<schema>)1
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"></schema>
name="TESTDB": 定义了一个逻辑数据库,名称为TESTDB,它代表一个逻辑上的数据库,可以有多个数据节点(物理数据库)参与其中。必须要与server中的名字对应checkSQLschema="false": 关闭了 SQL 校验功能,Mycat 不会对 SQL 语法进行验证。sqlMaxLimit="100": 定义了 SQL 查询的最大限制,最大查询结果行数为 100。dataNode="dn1": 指定了逻辑数据库TESTDB使用的数据节点dn1,dn1是一个物理数据节点的名称
数据节点配置 (
<dataNode>)1
<dataNode name="dn1" dataHost="node1" database="mytest"/>
name="dn1": 定义了数据节点dn1的名称。数据节点是 Mycat 中物理数据库的映射。这里的名字,必须要与schema中的dataNode相同dataHost="node1":dn1所关联的数据主机是node1,数据主机是物理数据库的服务器。database="mytest": 该数据节点所使用的数据库是mytest,即 Mycat 会路由到名为mytest的数据库。
数据库主机配置 (
<dataHost>)1
2<dataHost name="node1" maxCon="1000" minCon="10" balance="3" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat> select test()</heartbeat>name="node1": 数据主机名称是node1,它代表一组物理主机,可以包含多个写主机和读主机。maxCon="1000": 数据库连接池的最大连接数为 1000。minCon="10": 数据库连接池的最小连接数为 10。balance:“0”:不开启读写分离
“1”:全部的readHost和stand by writeHost参与select语句的负载
“2”:所有读操作随机在readHost和writeHost上分发
“3”:所有读请求随机分发到writeHost对应的readHost上执行
writeType="0": 所有写操作发送到配置的第一个writeHost,第一个挂掉切换到还生存的第二个writeHostdbType="mysql": 数据库类型是 MySQL。dbDriver="native": 数据库驱动类型为本地驱动(native)。switchType="1":- “-1”:不自动切换
- “1”:自动切换,根据心跳select user()
- “2”:基于MySQL的主从同步状态决定是否进行切换 show slave status
slaveThreshold="100": 当主节点的负载超过 100 时,Mycat 会切换到从节点。心跳配置
1
<heartbeat> select test()</heartbeat>
heartbeat: 定义一个 SQL 查询,用来检测数据库连接是否活跃。这里使用了select test(),目的是保持连接的活跃性。
写主机和读主机配置 (
<writeHost>和<readHost>)1
2
3
4<writeHost host="192.168.135.129" url="192.168.135.129:3306" user="root" password="123456">
<readHost host="10.157.219.148" url="10.157.219.148:3306" user="root" password="123456"/>
</writeHost>
<writeHost host="10.157.219.148" url="10.157.219.148:3306" user="root" password="123456"/>writeHost: 配置写主机,所有的写操作将会发送到该主机。在此例中,第一个写主机是192.168.135.129,第二个写主机是10.157.219.148。写主机是负责处理数据库写操作的节点。readHost: 配置读主机,读操作将会发送到该节点。读主机的目的是分担读取操作的负载,通常用于主从复制架构。此例中,192.168.135.129的主机有一个从主机10.157.219.148,它用于处理读请求。- 当第一和writeHost出问题时,会切换到第二个writeHost
启动mycat
1
mycat start
报错:查看logs/wrapper.log文件
1
2
3
4
5
6INFO | jvm 5 | 2024/12/05 15:47:40 | Unrecognized VM option 'MaxPermSize=64M'
INFO | jvm 5 | 2024/12/05 15:47:40 | Error: Could not create the Java Virtual Machine.
INFO | jvm 5 | 2024/12/05 15:47:40 | Error: A fatal exception has occurred. Program will exit.
FATAL | wrapper | 2024/12/05 15:47:40 | There were 5 failed launches in a row, each lasting less than 300 seconds. Giving up.
FATAL | wrapper | 2024/12/05 15:47:40 | There may be a configuration problem: please check the logs.
STATUS | wrapper | 2024/12/05 15:47:40 | <-- Wrapper Stopped原因时java8以后不再支持
MaxPermSize配置,我们当前时JDK21,修改MyCat的启动配置文件wrapper.conf,注释调MaxPermSize1
# wrapper.java.additional.3=-XX:MaxPermSize=64M
然后就启动成功了
通过查询日志验证读写分离是否成功
1
2show variables like 'general%';
set global general_log=on;分别执行读写操作,对比查询日志
可以通过一下命令登录到MyCat管理端
1 | mysql -h xxx.xxx.xxx.xxx -p 9066 -u root -p |